
评论系统数据库从Leancloud更换为Deta
前言
因为我的waline评论系统选了Leancloud数据库,最早是用的国内版,速度还行,后来变更通知不再为国内用户服务,需要备案才能使用,听到这通知我傻眼了!现在真是不走备案不让用了啊!它后来出了国际版,我就去用国际版了,就是速度非常慢——但也勉强还能用……后来我去琢磨了Mongodb,完全看不懂啊~~好复杂的样子,可能是我太笨了 这几天也看了Mongodb教程,也还是一头雾水,就是最后的多IP地址总是搞不明白,于是乎又放弃了……
这几天也看了Mongodb教程,也还是一头雾水,就是最后的多IP地址总是搞不明白,于是乎又放弃了……
后来想到我的博友小波他是换了Deta Base做数据库了,我也是试试吧!万一这次成功了呢!
于是开始动手啦~
备份评论数据
首先要提前备份评论数据!Leancloud和waline后台的数据都要导出来,防止后续导入会出错噢。这是必要流程!
Leancloud导出要点你的评论应用,点击“数据存储”——“导入导出”,然后在右边选择“数据导出”页面,在下方勾选限定Class,确认是否勾上全选,最后可以导出啦!
文件会发到你的邮箱,文件是比较长的一串数字,记得改个名加个日期以防混乱,比如“Leancloud评论导出 2024-01-01”这样的名称。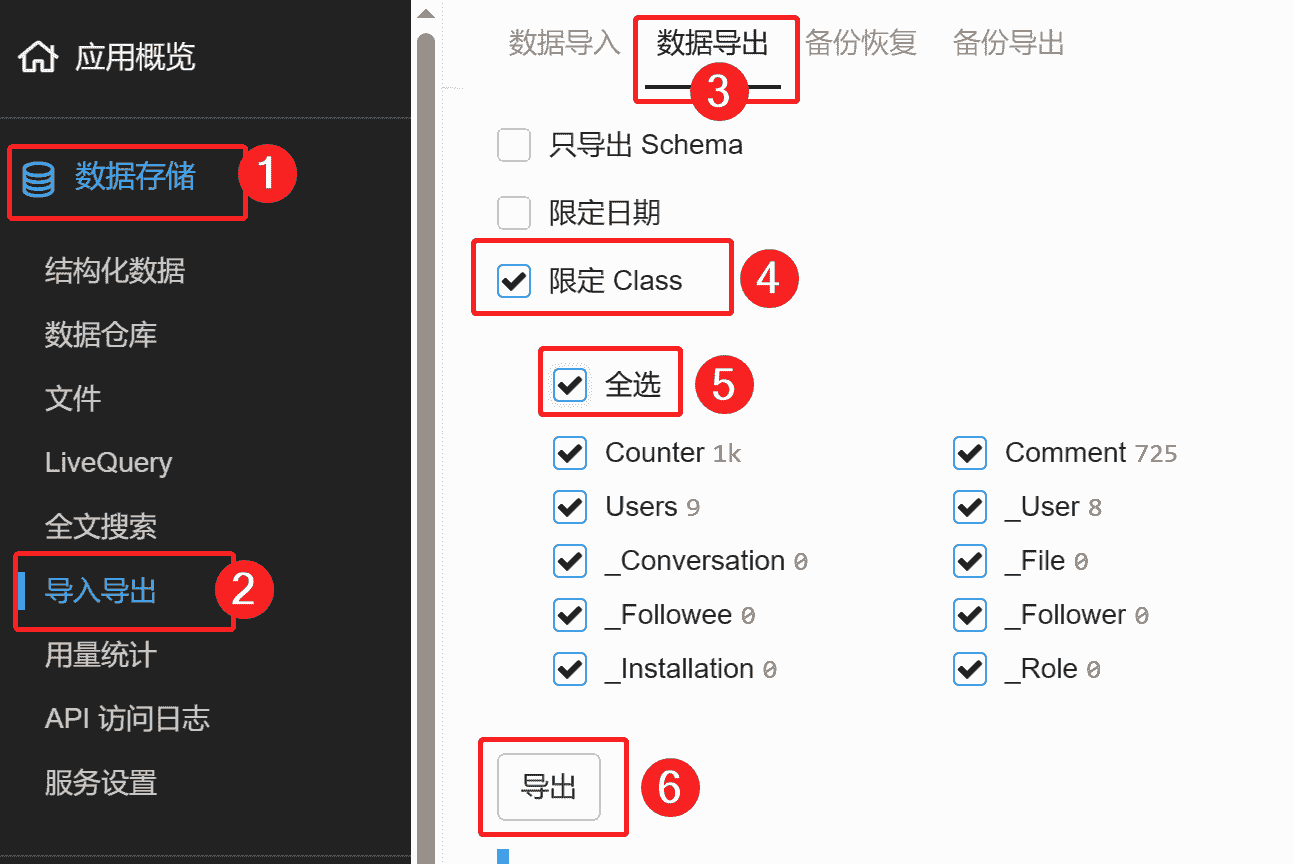
waline后台是你部署平台的后台,在后面地址输入/ui就能进入管理后台了。例如:
https://waline.com/ui |
在左上角点击“管理”——“导出导出”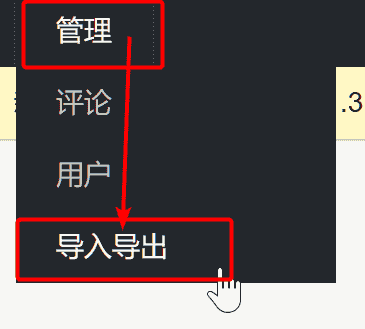
然后点击“导出”,稍等一会儿,浏览器就会出现文件下载了。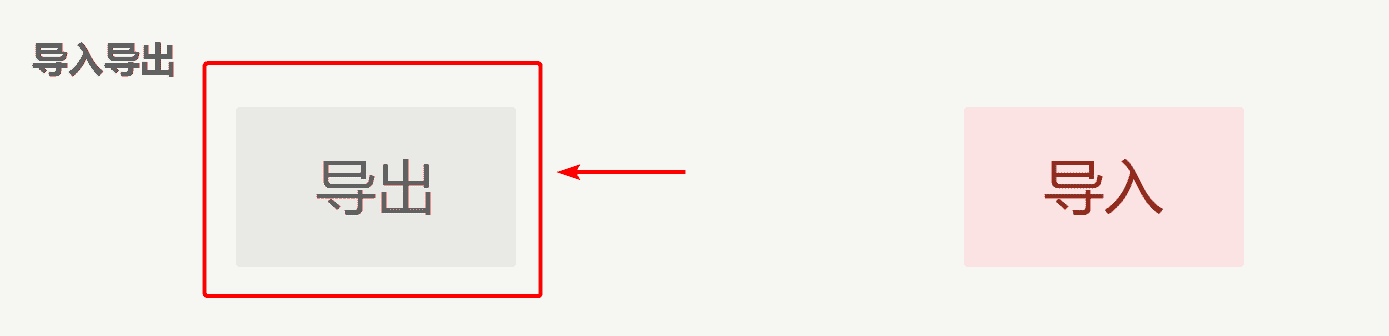
如果导出没反应,就多点几次,浏览器就会出现下载文件的。
json数据拆分
从后台导出的json文件较大,比如我评论系统有1000多数据文件就有1.1M,如此大的文件在后续导入过程中会出现导入错误的情况,这时候我们需要分批导入,也就是把数据拆分出来!分批导入就不会有问题了!由于我不会写Python代码,于是我去向chatGPT请教了下,它帮我写出了拆分代码,我也放出来给大家参考,我是waline评论系统,你们要根据自己的评论系统情况更改。如果你的数据量较少,100条左右的话就不用拆分了,直接导入即可。
把下面代码复制到文本编辑器,另存为waline_chunk.py文件,其中input_file和chunk_size请自己修改。
# 将waline评论数据json文件拆分,按每100块数据拆分成多个小文件 |
然后打开命令提示符输入下面命令就可以了。
Python waline_chunk.py |
Deta部署
现在Deta改版了,网页大变样!之前还是需要命令行操作呢,现在全程只需要在网页操作了,十分方便~对噢,想起来以前官方也说过未来会出web UI版,现在已经实现了,真不错!
我是在vercel部署了,就不用在Deta部署了,如果想要在Deta部署,可以点击下面waline文档链接操作,很好弄的!
链接:Deta 部署
部署完后界面长这样!它是一种卡片形式的,刚部署完waline的卡片特别小,你需要自己去拖动变大,下次就会好找了~
开发人员命令行操作
如果你是开发人员,可以下载Space-Cli输入命令行操作,官方仓库下载:https://github.com/deta/space-cli/releases
官方文档也有命令行帮助:https://deta.space/docs/en/build/reference/cli
我还以为用Space-Cli能克隆下项目呢,没找到相关的选项,看来waline是只能在网页操作了,省去这一步骤了。
配置环境变量
接下来配置环境变量,如果部署在Deta上,就不需要配置环境变量,Waline默认会使用Deta Base作为数据库存储数据。如果是部署在其它地方,需要配置以下环境变量。
| 环境变量名称 | 值 |
|---|---|
| DETA_PROJECT_KEY | deta项目的密钥 |
Deta
如何配置环境变量呢?在deta项目用鼠标悬停会出现个黑色圆圈,点击它就会出现选项,点击“Open settings”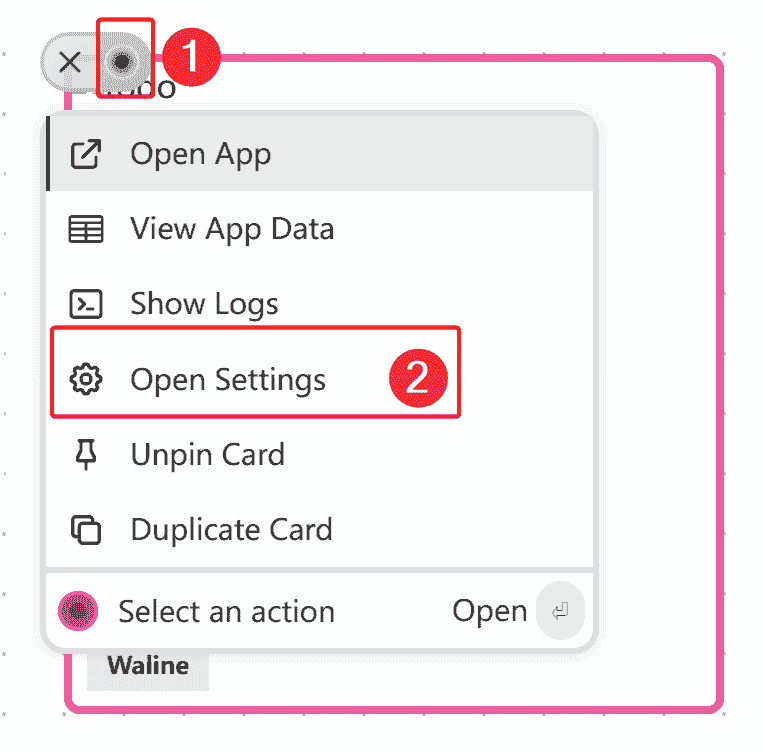
然后点击Configuration,下面就是环境配置了,可以边看waline官方文档来对照配置。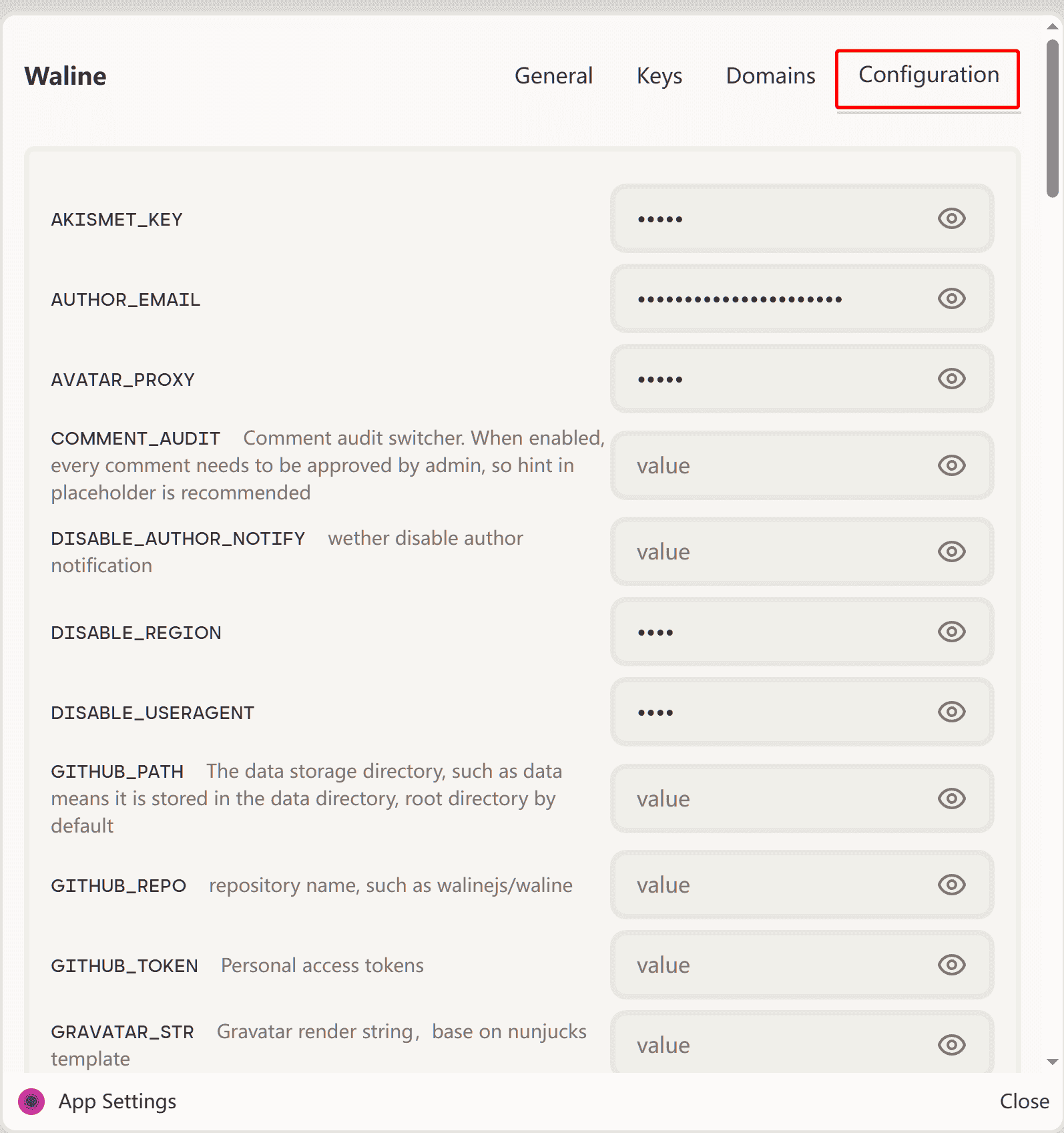
需要注意:Deta环境配置不宜写过长的代码,也就是邮件通知配置无法写入自定义的Html代码,只能用默认模板了,不知道以后官方能不能放开环境变量的长度。
另外也要注意下邮件通知是否顺利,若是无法收到邮件,请更换别的邮箱运营商。就我目前测试QQ邮箱无法收到邮件通知,gmail可以收到通知。
vercel
如果是部署在其他平台上,比如vercel,我们就需要创建Key,才能在其他平台上使用deta的数据库。
依然是打开“Open settings”设置,点击keys,在下方点击Create new deta Key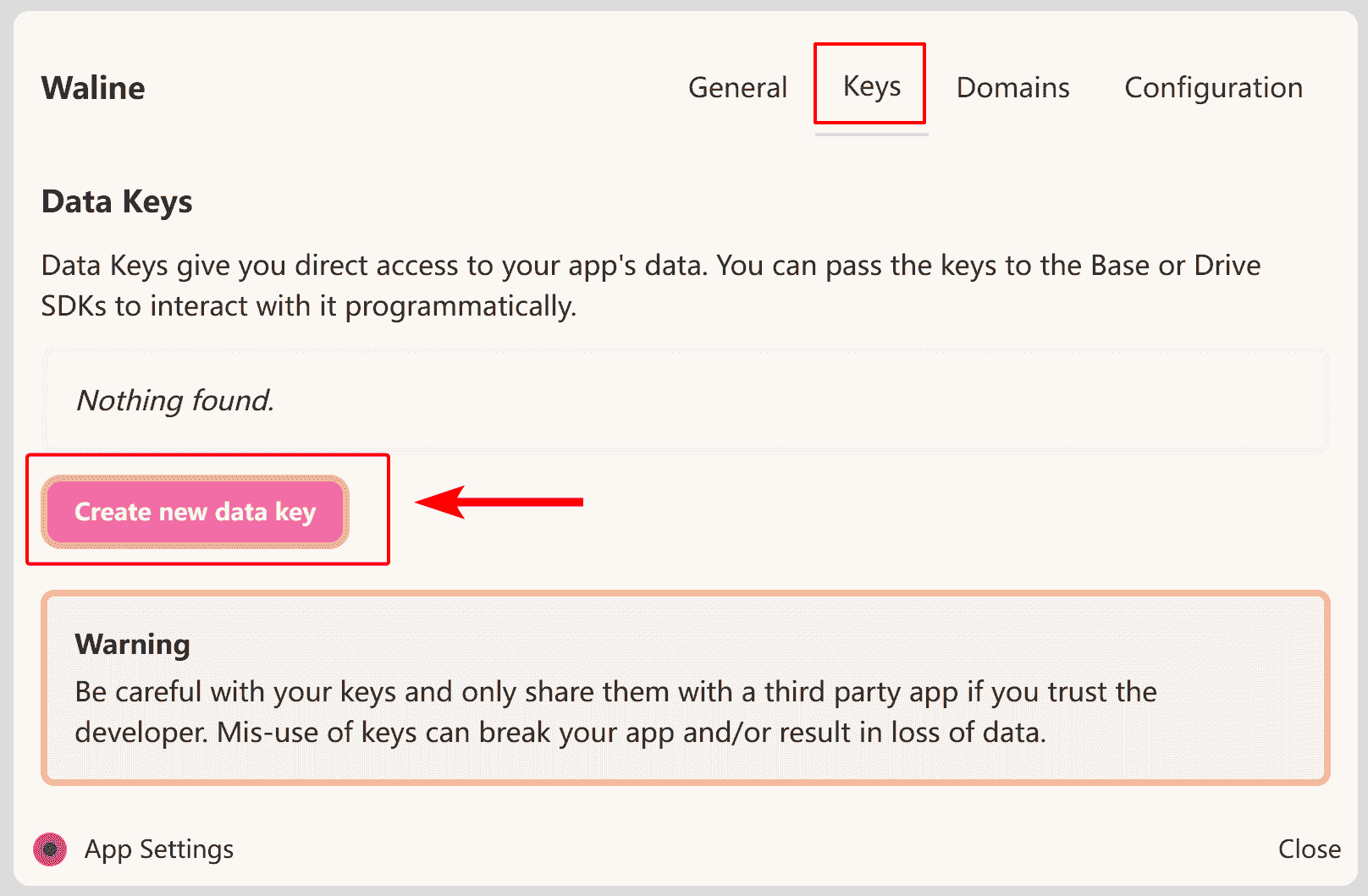
然后就会自动生成Key密钥啦!记住这个密钥只出现一次,要赶紧点击右侧的复制按钮,复制下来到文本里,以防忘记!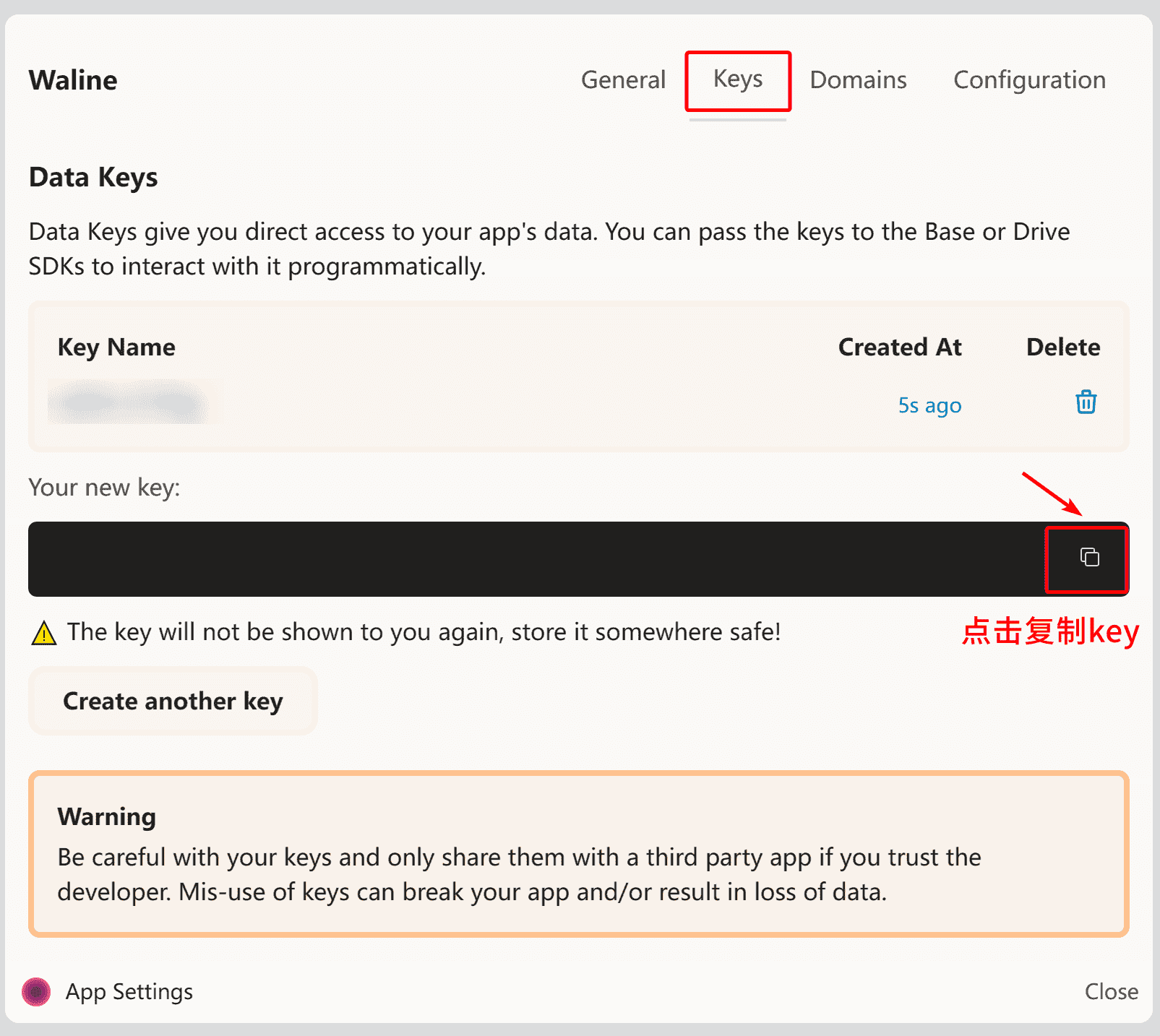
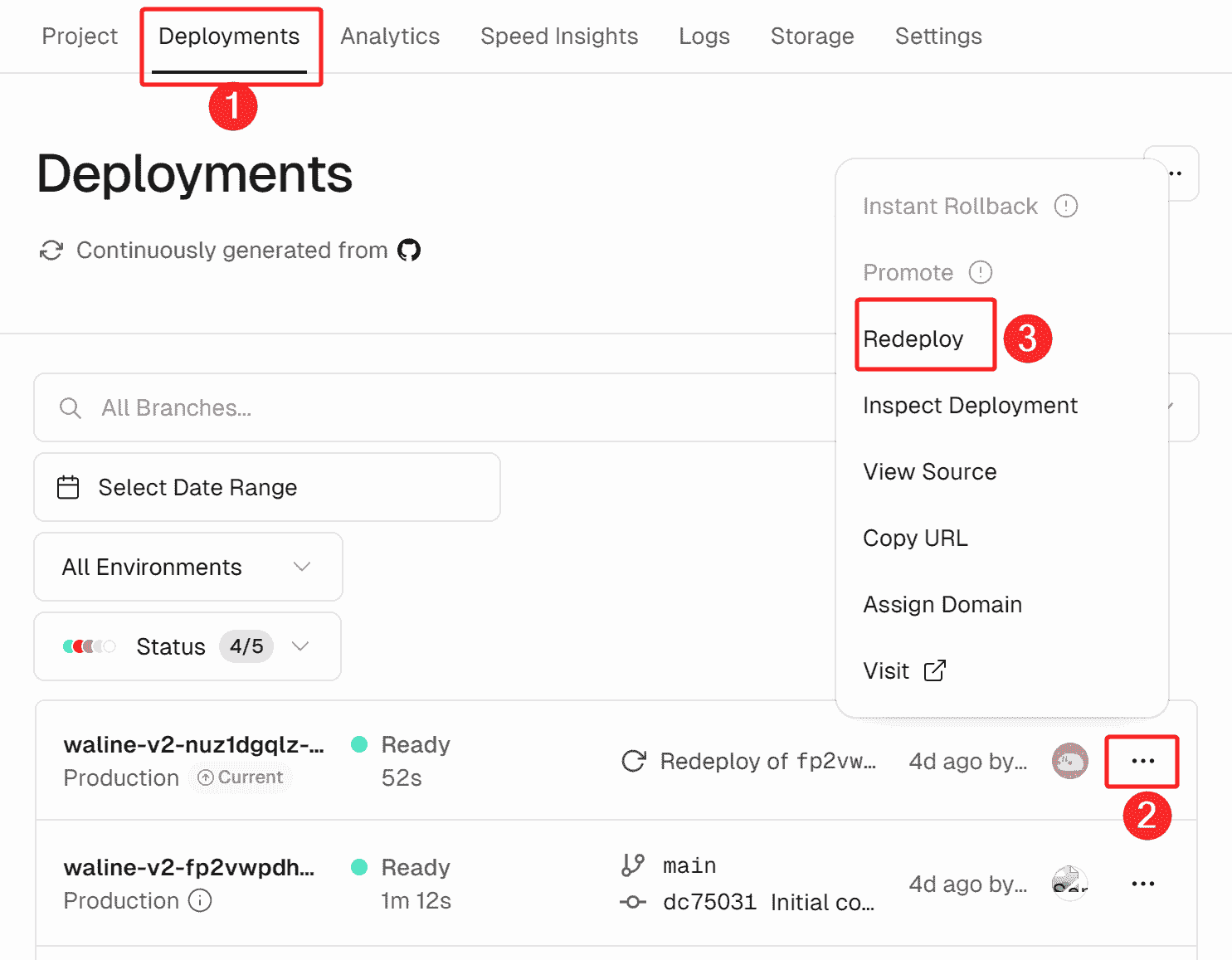
然后我们去vercel评论系统项目,点击Settings——Environment Variables,在右侧的“Key”填入DETA_PROJECT_KEY,后面的value就是咱们刚才创建的Key啦!填完后点击Save即可。
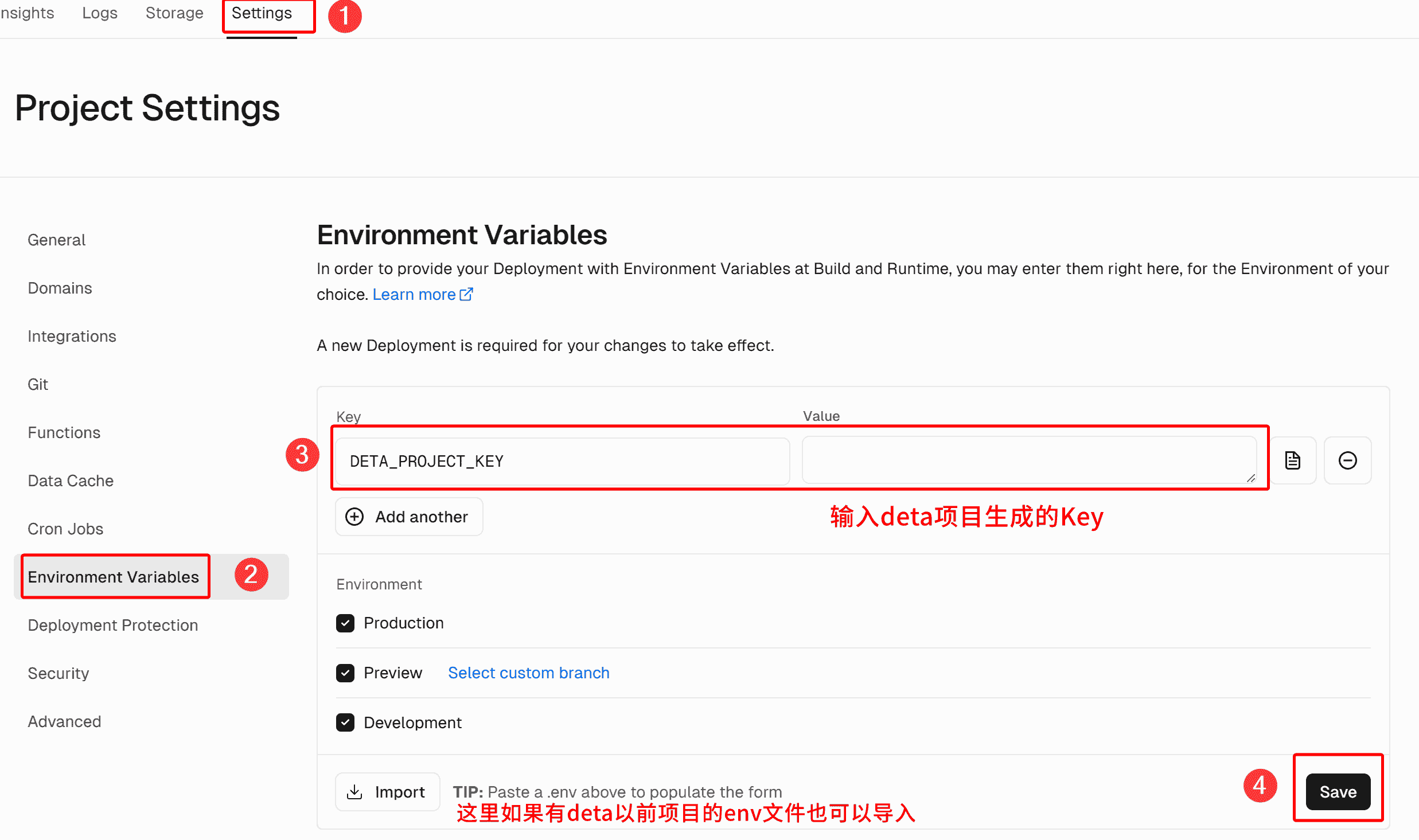
填完后我们要重新部署,因为环境变量还没有更新生效,点击上方的Deployments,点击第一个构建的...,下拉表点击Redeploy,然后确定Redeploy即可。
数据库迁移
从一个部署平台迁移到另一个部署平台,评论后台是不一样的,需要重新注册,第一个注册的人就会成为全局管理员,才能使用后台。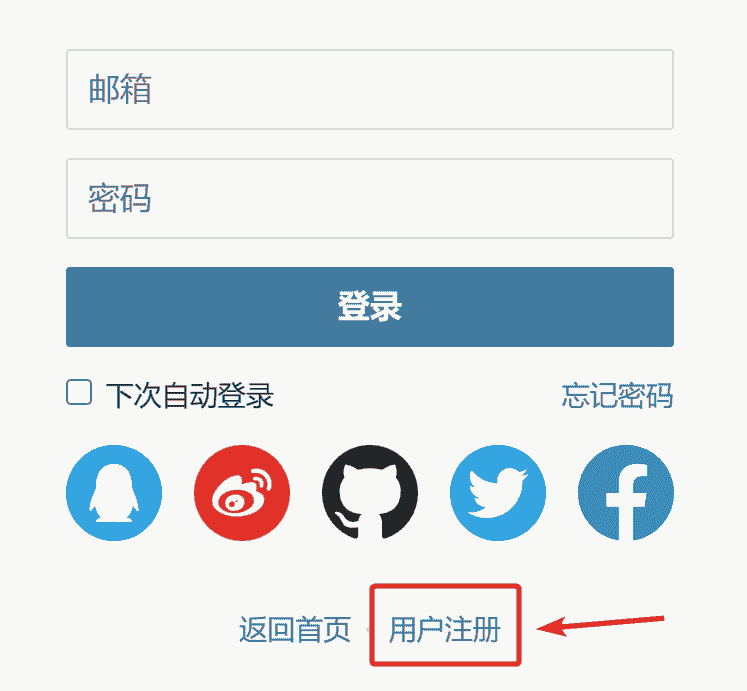
在地址栏后输入/ui即可进入评论系统后台。
在左上角点击“管理”——“导出导出”
点击“导入”
选择之前下载好的json文件,然后就会开始导入了。
在这过程当中我遇到了504错误,我查了下,可能是因为vercel有限制,全部导入会有问题,要分批导入,感觉好像是只能导入100条数据,就用前面json数据拆分那部分一个个导入吧!
不过我尝试了两次仍然还是504错误,我觉得可能数据量太多了vercel不受理,我就换成在deta后台试试了,结果它导入很快!看来是部署平台的问题啊,如果导入失败了,那么就再导入一次,它就导入成功了!看下博客评论效果吧,很完美迁移过来了~
注意 评论导入会覆盖前面的评论,会导致之前的评论也删除,vercel导入有限制,我建议是在Deta后台导入,我尝试了很多次导入,都很顺利导入成功了!推荐用Deta部署在后台导入~查看数据
怎么查看数据呢?在Deta项目中点击黑色圈圈,点击View App Date,在Base下就可以看到评论数据啦!别忘了开启Edit Mode,就可以对数据编辑了。
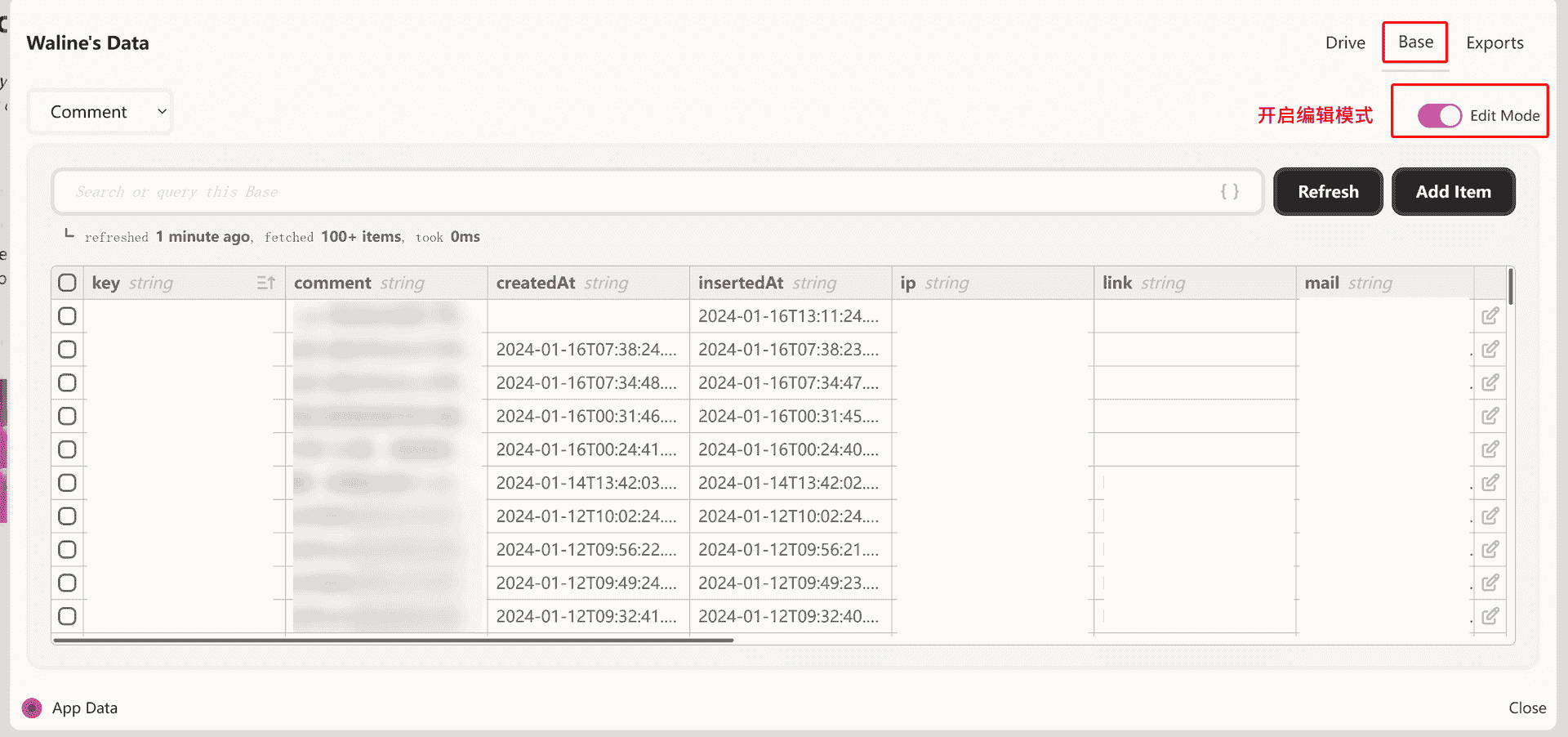
和Leancloud操作差不多,都是表格形式的,很直观,就是没有批量操作,以后应该会出个批量操作功能。
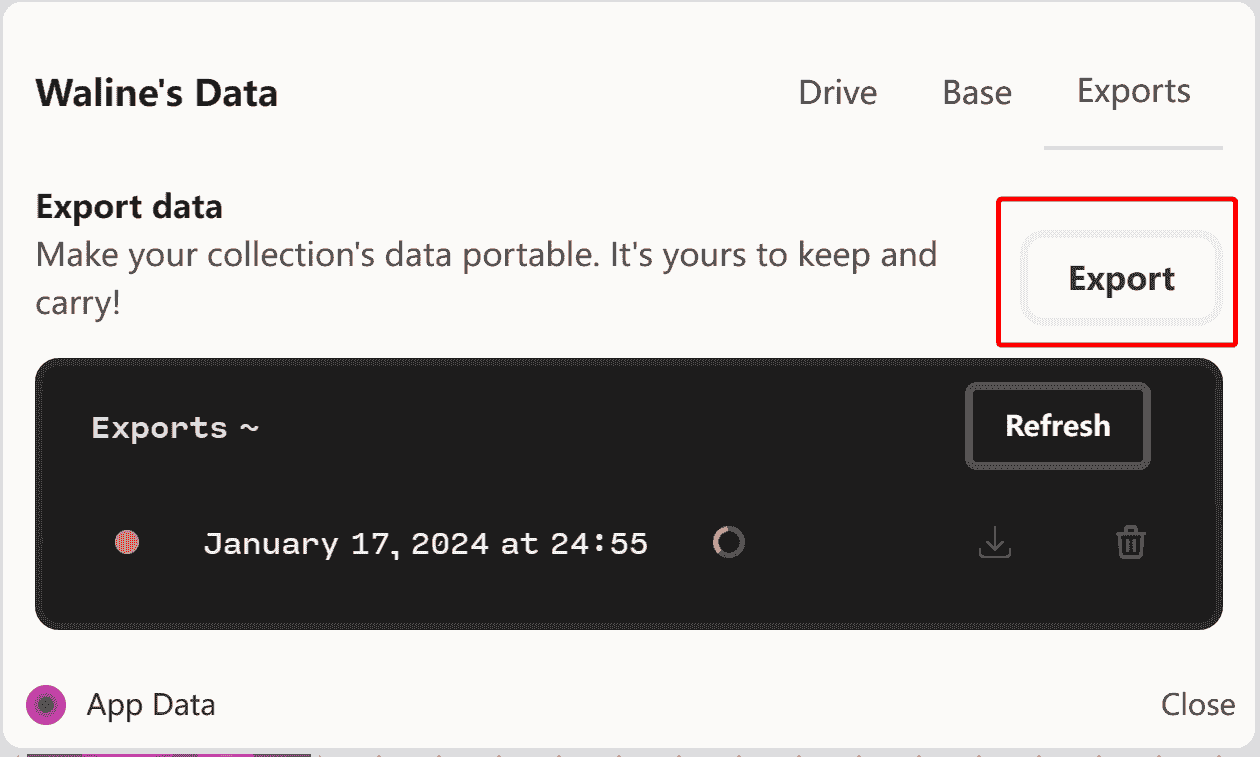
对了,Deta也可以导出数据,在Export页面点击Export按钮,就可以导出了!稍等一会儿,然后再点击下Refresh刷新下,就可以下载了!
Deta数据库comment表字段说明
| 字段名 | 说明 |
|---|---|
| key | 评论的唯一标识,回复对应关系使用 |
| comment | 评论内容 |
| insertedAt | 插入时间 |
| ip | 评论者ip |
| like | 评论爱心统计 |
| link | 评论者网站地址 |
| 评论者邮件地址 | |
| nick | 评论者昵称 |
| objectId | 评论者的评论唯一标识id |
| pid | 回复的对应评论id |
| rid | 整条评论的id |
| status | 审核状态 |
| ua | 浏览器 |
| url | 页面地址 |
| user_id | 注册帐号id |
| createdAt | 创建时间 |
| updatedAt | 更新时间 |
Deta数据库Counter表字段说明
这一块应该是阅读量统计计数的数据
| 字段名 | 说明 |
|---|---|
| createdAt | 创建时间 |
| time | 阅读量次数 |
| updatedAt | 更新时间 |
| url | 关联文章地址 |
| objectId | 唯一标识ID |
最后还要检查下导出的json数据是否有漏下的评论,就去后台补上,这就要花时间手动检查了。早期评论有些显示不出来,可能是因为没有添加 status 数值,添加上就可以显示了。因为waline每个版本都在更新功能,所以需要自己仔细排查。
在json数据添加审核通过属性:
"status": "approved", |
还有一些回复评论的objectId指向问题也要排查,早期评论是这样:
<a class=\"at\" href=\"#454sdf4f84sdkflakh\">@SaraKale |
需要把它们都改成这样的格式,才能正确显示出来。
[@SaraKale](#454sdf4f84sdkflakh): |
其他修改
url地址路径批量重定向
由于我的站点url路径末尾是加了.html,以前部署的时候没有想到镜像站的同步问题,后来才发现镜像站netlify/Cloudflare路径和github路径不一样,必须要关闭Hexo选项的pretty_urls选项末尾的.html才能同步评论数据。为什么会部署不一样哇,简直无语……
后来我去问了下ChatGPT,原来是为了提高SEO啊……
Netlify默认情况下会处理网站的URL,将末尾的.html去掉,以提供更简洁的URL结构。这是一种常见的做法,有助于提高网站的用户友好性和搜索引擎优化(SEO)。
不过我还是让它帮我写个脚本,把末尾修改为斜杠吧,为了能让访客都能看到评论,我还是去掉html后缀了,这样能随时交流了~你也可以根据自己的需求修改。
我顺便去Cloudflare也做页面永久重定向了,以前的文章路径会跳转新的路径,不会有404问题了~
# 在/blog/posts/末尾插入斜杠/ |
也可以在网站根目录创建_redirects文件,添加下面的规则,会把页面全部重定向。
/* /:splat.html 200 |
或者在netlify.toml文件中:
[[redirects]] |
json时间排序
从Deta后台导出json文件我发现,Deta评论的Key值似乎是以数值较小的排在前面,如:
9007199254468113 |
所以最新评论排在前面是因为Key值数值较小,所以才能看到最新评论,怎么会如此……难道不是最新评论的Key值最大吗,因为是慢慢增加的啊,完全搞不懂Deta的排列顺序,怪不得在导入的时候有评论是排序错乱了……
所以我又去找chatGPT帮我写个时间排序脚本,这样评论不会错乱了!
# ======================== |
好了,现在已成功换成Deta数据库了,这下应该加载很快了吧!终于摆脱掉Leancloud了!呜呜果然要勇敢尝试下才知道呢,再也不用看复杂的数据库了!我觉得Deta就挺好的!哈哈哈哈!
小伙伴看看有没有遇到什么bug~有问题就在评论反馈吧!
参考文章


如果遇到评论加载不出来,请不要担心,稍等一会儿,等待服务器后台修复即可,或者过一段时间来看看~